正規表現で日本語マッチを失敗させないコツ
電話番号・日付・ひらがなをテキストから探したい。正規表現テスターでパターンを試しながら組み立てると、日本語テキストにも正確に機能するパターンが作れます。
公開 更新 読了目安 約5分
この記事の要点
- パターンを入力するとマッチ箇所が即座に黄色くハイライトされる
- 日本語テキストでは英語向けのパターンがそのまま使えないケースがある
- ひらがな・カタカナ・漢字は文字コード範囲で指定するパターンを使う
- 置換プレビューで変換結果をその場で確認してから本番実行できる
- 入力したパターンもテキストもすべてブラウザ内だけで処理される
目次
「テキストから電話番号だけを取り出したい」「日本語が含まれる文章で特定のパターンを探したい」。そんな場面で、正規表現テスターを使うとパターンを試しながら結果をリアルタイムで確認できます。書いたパターンがどこにマッチするか黄色くハイライトされるため、修正しながら正確なパターンを組み立てられます。
「パターンが思い通りに動かない!」あるある 3 つ
テキストから特定のデータを取り出そうとしたとき、こんな場面で困ったことがあるでしょうか。
「電話番号だけ取り出したかったのに、数字全部がマッチした」。数字を探すパターン(\d+)を書いたところ、住所の番地や日付の数字まで全部ハイライトされてしまいます。電話番号の形式(3桁-4桁-4桁)だけを取り出すには、もう少し具体的なパターンが必要です。
「ひらがなだけ取り出したかったのに何もマッチしなかった」。英数字向けのパターンをそのまま日本語テキストに使うと、ひらがな・カタカナ・漢字はマッチしません。日本語の文字には、英語テキストと異なる範囲指定が必要です。
「途中まで合っていたが、日本語の直後だと失敗する」。英語では単語の区切りを示す記号(\b)が使えますが、日本語テキストでは機能しません。日本語が混在した文章でパターンを使うと、意図した場所でマッチが止まることがあります。
正規表現テスターの使い方
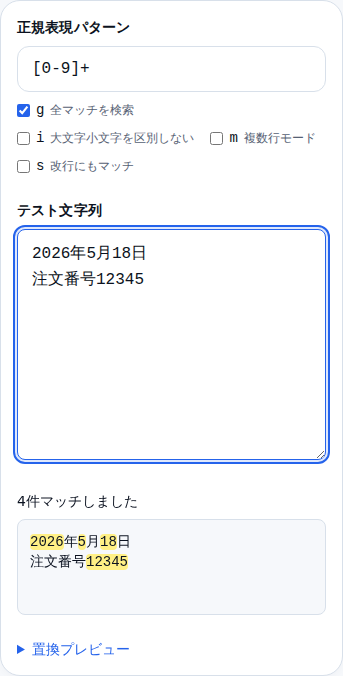
正規表現テスターを開くと、上段に「正規表現パターン」の入力欄、下段に「テスト文字列」の入力欄が表示されます。
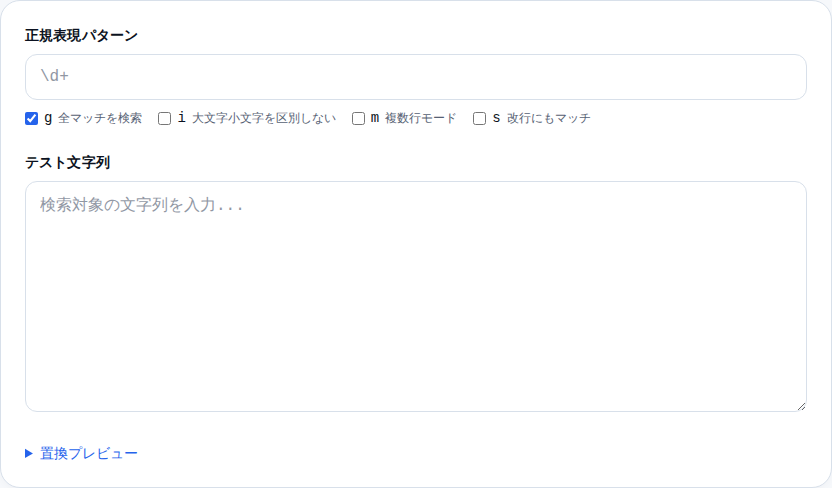
ステップ 1: 上段の「正規表現パターン」欄にパターンを入力します。
ステップ 2: 下段の「テスト文字列」欄に確認したい文章を貼り付けます。
ステップ 3: 入力と同時にリアルタイムで結果が更新されます。マッチした部分が黄色くハイライトされ、件数も表示されます。
電話番号を探すパターン
電話番号の形式「090-1234-5678」を探すには、「\d{3}-\d{4}-\d{4}」というパターンを使います。「\d」は数字1文字を、「{3}」は3回の繰り返しを意味します。
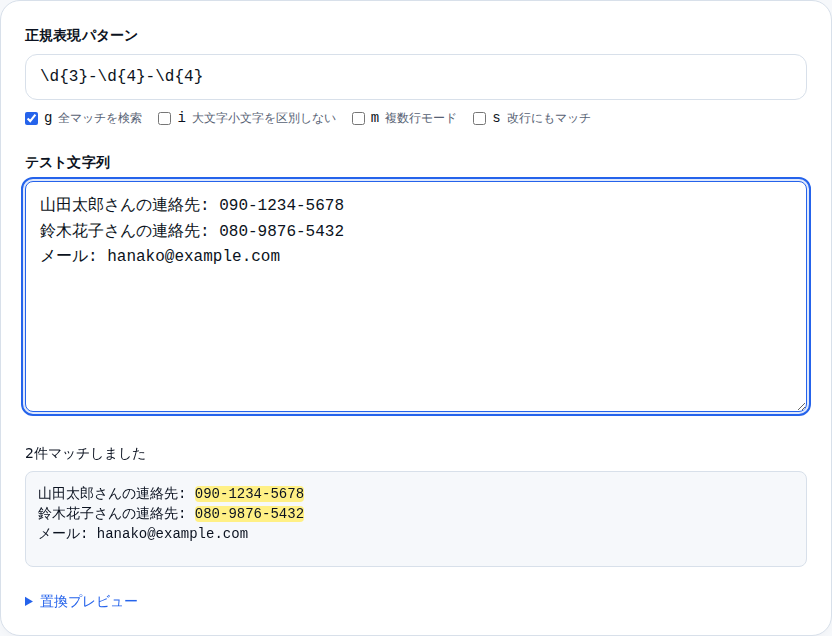
連絡先リストや名簿のテキストに貼り付けてパターンを試すと、どの番号が取り出せるか即座に確認できます。
日本語の文字を取り出すパターン
「ひらがなだけ取り出す」という操作は、英語テキストよりも少し特別なパターンが必要です。
ひらがな(「あ」から「ん」)の範囲は「[ぁ-ゖ]」で指定できます。ぁ はひらがなの最初の文字「ぁ」、ゖ はひらがなの最後の文字「ゖ」に対応する番号です。「+」をつけると2文字以上の連続したひらがなをまとめて取り出せます。
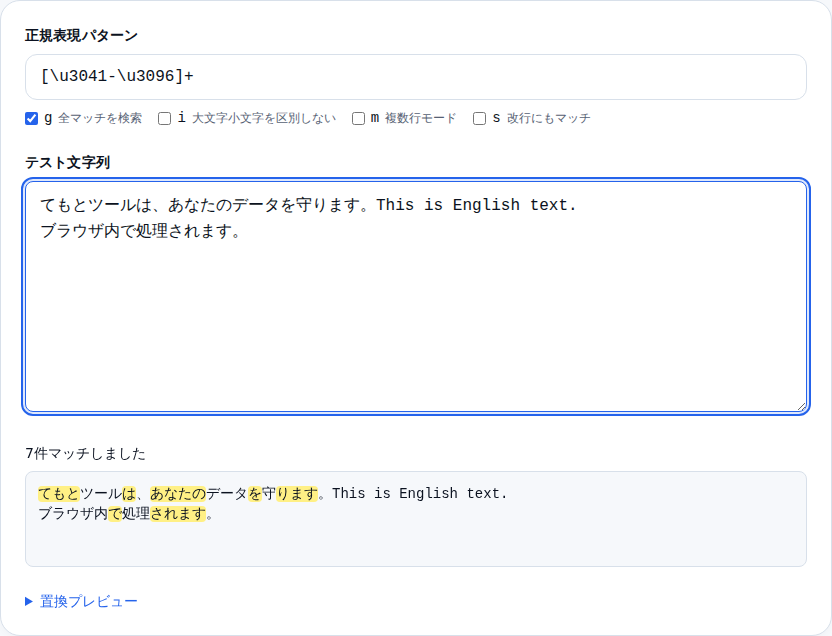
よく使う日本語文字の範囲指定は次の通りです。
| 対象 | パターン | 意味 |
|---|---|---|
| ひらがな | [ぁ-ゖ] | あ〜ん、拗音含む |
| カタカナ | [ァ-ヶ] | ア〜ン |
| 漢字 | [一-鿿] | CJK統合漢字(常用漢字を含む) |
| 全角数字 | [0-9] | 0〜9 |
置換プレビューで変換結果を確認する
マッチしたパターンを別の文字列に置き換えるとどうなるか、実行前に確認できます。
「置換プレビュー」を開き、置換後の文字列を入力します。たとえば電話番号「090-1234-5678」を「(090) 1234-5678」形式に変えるには:
- パターン:
(\d{3})-(\d{4})-(\d{4}) - 置換後:
($1) $2-$3
と入力します。$1・$2・$3 は括弧で囲んだグループに対応します。
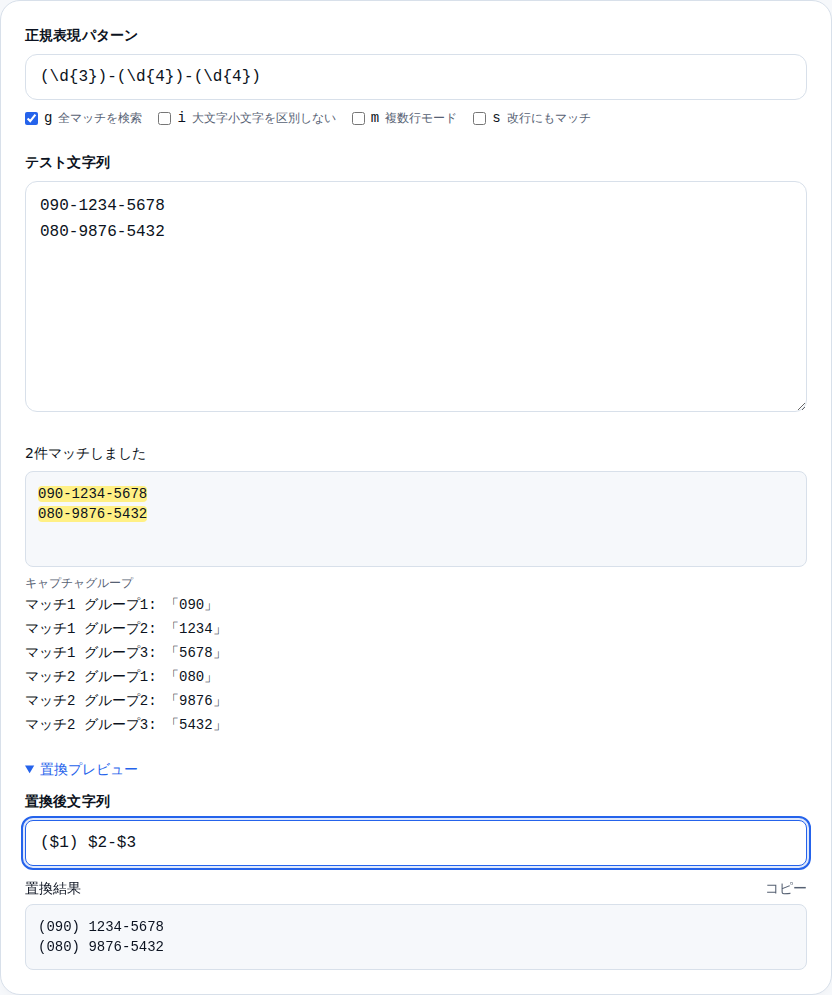
スプレッドシートの REGEXREPLACE 関数や外部ツールで実行する前に、ここで確認するのが安全です。期待通りの結果になるか事前に確かめられます。
こんな場面で使える
名簿・リストから特定の情報を取り出す
名簿テキストから電話番号やメールアドレスだけを抽出したいとき、パターンを試しながら目的のデータをハイライトできます。フラグ「i」をオンにすると、メールアドレスの大文字小文字混在にも対応します。
スプレッドシートの関数で使うパターンを事前に確認
Google スプレッドシートには REGEXMATCH・REGEXEXTRACT・REGEXREPLACE があります。スプレッドシートに適用する前に、このツールでパターンの動作を確認しておくと安心です。
日付・金額のフォーマットを統一する
「2026年5月18日」「2026/05/18」「2026-05-18」など混在した日付形式を統一したいときに使えます。各形式のパターンを試して、置換プレビューで変換結果を確認できます。
使用例
たとえば、事務代行フリーランサーが「800行のテキストから電話番号だけ抜き出してほしい」と依頼された場面です。
正規表現テスターで電話番号パターンを試すと、マッチ箇所がすべてハイライトされます。パターンが決まったら、スプレッドシートの REGEXEXTRACT 関数に同じパターンを使って一括抽出できます。
安心して使えるポイント
入力したパターンもテスト文字列もブラウザの中だけで処理されます。顧客リストや個人情報を含む文章を貼り付けても、外部サーバーには一切送信されません。
関連ツール
- テキスト置換ツール — 正規表現なしで単純な文字列置換をしたいとき
- JSON整形ツール — テキストデータをJSON形式で整理・確認するときに
- URLエンコード・デコードツール — URLに含まれる特殊文字を変換するときに
まとめ
正規表現で日本語テキストを扱うときの3つのコツをまとめます。
- ひらがな・カタカナは
[ぁ-ゖ]形式で範囲指定する。英語向けの文字クラスは日本語には適用されない - 電話番号・日付などは形式を具体的に書く。
\d+だけでなく\d{3}-\d{4}-\d{4}のように桁数も指定するとより正確にマッチする - 置換プレビューで本番実行前に確認する。スプレッドシートや外部ツールで実行する前にここで結果を確かめると安心
正規表現テスターでパターンを試しながら組み立てると、失敗の回数を減らせます。
補足: 開発者の方へ
JavaScript の \b(ワード境界)は ASCII の \w との境界を検出するため、日本語文字はすべて \W として扱われます。\b東京\b は「東京」の前後が ASCII 英数字でない限りマッチしません。
日本語の単語境界を扱うには、前後に空白や句読点があることを前提としたパターンか、形態素解析との組み合わせが必要です。
このツールは new RegExp(pattern, flags) にフラグ u(Unicode モード)を常に付与しています。Unicode モードでは構文エラーが早期に検出され、サロゲートペアを含む文字(絵文字など)も1文字として扱われます。ひらがな・カタカナのコードポイント範囲は [ぁ-ゖ](ひらがな)と [ァ-ヶ](カタカナ)が常用の範囲です。
あわせて読みたい
同じテーマ・関連ツールの記事です。