Intl.Segmenterで「人間が見て1文字」を扱う完全ガイド
絵文字やZWJ結合文字をJavaScriptで正確に1文字として数えるにはIntl.Segmenterが必要です。String.lengthとの違い・ブラウザ対応・実装パターンを解説します。
公開 更新 読了目安 約5分
この記事の要点
- String.lengthは内部のコード単位を数えるため絵文字で「見た目と違う数値」になる
- 書記素クラスタとは人間が1文字と認識する最小単位でIntl.Segmenterで取得できる
- Intl.SegmenterはChrome 87・Firefox 125・Safari 16.4・Node.js 16以上で利用可能
- 文字数制限フォームやテキスト切り捨てではIntl.Segmenterを使うのが正解
- 文字数カウンターで書記素クラスタ・String.length・UTF-8バイト数を同時に確認できる
目次
ブログのフォームで「あと○文字」を表示するとき、家族絵文字 👨👩👧👦 が「11文字分」消費されることがあります。ユーザーが困惑するのは、String.length が内部の符号単位を数えるためです。Intl.Segmenter を使うと、絵文字も結合文字も「見た目通りの1文字」として正確にカウントできます。
String.length が「人間の感覚」と異なる理由
JavaScript の文字列は UTF-16 で内部管理されます。UTF-16 では、基本多言語面(BMP: U+0000〜U+FFFF)の文字は1コード単位で表現されます。それ以外の文字(BMP外)は2コード単位のサロゲートペアを使います。
'a'.length // 1 ← BMP文字
'あ'.length // 1 ← BMP文字
'𝕳'.length // 2 ← BMP外(U+1D573)サロゲートペア
'😀'.length // 2 ← 絵文字もBMP外(U+1F600)
'👨👩👧👦'.length // 11 ← ZWJ結合 + サロゲートペア×4'👨👩👧👦' が11になる理由は、この絵文字が5文字を**ZWJ(ゼロ幅接合子)**でつないだシーケンスだからです。
👨 + ZWJ + 👩 + ZWJ + 👧 + ZWJ + 👦
= 2 + 1 + 2 + 1 + 2 + 1 + 2 = 11 コード単位String.length はこの分解された単位を数えるため、見た目1文字が11と返ります。
書記素クラスタとは
**書記素クラスタ(grapheme cluster)**は、Unicode が定義する「人間が1文字と認識する最小単位」です。
- 基本文字 + 結合文字(例:
é=e+ 結合アクセント) - ZWJ で結合した絵文字シーケンス(例:
👨👩👧👦) - ハングル音節(例: 여 = ㅇ + ㅕ + 子音なし)
- 地域指示子ペア(例: 🇯🇵 = 🇯 + 🇵)
これらはどれも「見た目1文字」ですが、String.length では複数のコード単位として数えられます。
Intl.Segmenter の基本
Intl.Segmenter は ECMAScript Internationalization API の一部です。テキストを書記素・単語・文に分割するイテレータを返します。
const segmenter = new Intl.Segmenter('ja', { granularity: 'grapheme' });
function countGraphemes(str) {
return [...segmenter.segment(str)].length;
}
countGraphemes('hello'); // 5
countGraphemes('こんにちは'); // 5
countGraphemes('😀'); // 1 ← String.length は 2
countGraphemes('👨👩👧👦'); // 1 ← String.length は 11
countGraphemes('é'); // 1 ← e + 結合アクセント = 2コード単位segment() が返すイテレータをスプレッドして length を取ると、書記素クラスタ数が得られます。Intl.Segmenter インスタンスは再利用可能なので、カウント関数の外に1度だけ生成するのが効率的です。
ロケール引数の影響
granularity: 'grapheme' の場合、ロケール引数('ja')は書記素分割にほぼ影響しません。ロケールが重要になるのは granularity: 'word'(単語分割)のときです。日本語は空白を持たないため、ロケールを指定しないとうまく分割できません。
// 単語分割でのロケール差
const wordSegJa = new Intl.Segmenter('ja', { granularity: 'word' });
const wordSegEn = new Intl.Segmenter('en', { granularity: 'word' });
const text = 'てもとツールは便利です。';
[...wordSegJa.segment(text)].filter(s => s.isWordLike).map(s => s.segment);
// ['てもとツール', 'は', '便利', 'です'] ← 日本語ロケールで自然な分割String.normalize() との違い
String.prototype.normalize('NFC') は、同じ見た目の文字を同じコードポイントに正規化します。ただし、書記素クラスタ数を変えるわけではありません。
const e_accent = 'é'; // e + 結合アクセント(2コード単位)
const é = 'é'; // 合成済みé(1コード単位)
e_accent === é // false
e_accent.normalize() === é // true ← normalize で一致するが
e_accent.length // 2
e_accent.normalize().length // 1 ← NFC後は1コード単位
countGraphemes(e_accent) // 1 ← どちらも書記素クラスタは1フォームの文字数バリデーションでは、normalize 前後で String.length が変わるケースがあります。書記素クラスタ数で制限した方が、人間の直感と一致します。
ブラウザ・Node.js 対応状況
| 環境 | 対応バージョン |
|---|---|
| Chrome / Edge | 87+ (2020年11月〜) |
| Firefox | 125+ (2024年4月〜) |
| Safari | 16.4+ (2023年3月〜) |
| Node.js | 16.0+ (ICU full data 必要) |
| Deno | 1.8+ |
現在(2026年)の主要ブラウザシェアではほぼ全カバーです。古い環境をサポートする場合は @formatjs/intl-segmenter ポリフィルを使えます。ただし、バンドルサイズが増加する点に注意してください。
実装パターン集
パターン1: フォームの文字数制限
const segmenter = new Intl.Segmenter('ja', { granularity: 'grapheme' });
function CharLimitInput({ maxChars = 140 }: { maxChars?: number }) {
const [value, setValue] = useState('');
const count = [...segmenter.segment(value)].length;
const remaining = maxChars - count;
return (
<div>
<textarea
value={value}
onChange={e => setValue(e.target.value)}
maxLength={maxChars * 2} // サロゲートペアの最大倍率でざっくり制限
/>
<span style={{ color: remaining < 0 ? 'red' : 'gray' }}>
{remaining}
</span>
</div>
);
}maxLength 属性はコード単位ベースの制限です。書記素クラスタ数で制御したい場合は、UI 表示を Intl.Segmenter ベースにして送信時にバリデーションするのが確実です。
パターン2: テキストの切り捨て
function truncateByGrapheme(str, maxLength, ellipsis = '…') {
const segments = [...segmenter.segment(str)];
if (segments.length <= maxLength) return str;
return segments
.slice(0, maxLength - 1)
.map(s => s.segment)
.join('') + ellipsis;
}
truncateByGrapheme('こんにちは👨👩👧👦', 4);
// 'こんに…' ← 絵文字1文字分を正確に確保String.slice() はコード単位ベースのため、サロゲートペアの途中で切断して文字化けすることがあります。Intl.Segmenter を使うと安全に切り捨てられます。
パターン3: useDeferredValue との組み合わせ(React)
大量テキストに Intl.Segmenter を使うと処理が重くなる場合があります(10万字程度でも数十ms)。React の useDeferredValue を使うと入力中の UI が重くなりません。
const segmenter = new Intl.Segmenter('ja', { granularity: 'grapheme' });
function HeavyCounter() {
const [input, setInput] = useState('');
const deferred = useDeferredValue(input);
const count = useMemo(
() => [...segmenter.segment(deferred)].length,
[deferred]
);
return (
<>
<textarea onChange={e => setInput(e.target.value)} />
<p>書記素クラスタ: {count}</p>
</>
);
}文字数カウンターでの活用
文字数カウンターの「詳細集計」を開くと、書記素クラスタ数・String.length・UTF-8バイト数を並べて確認できます。
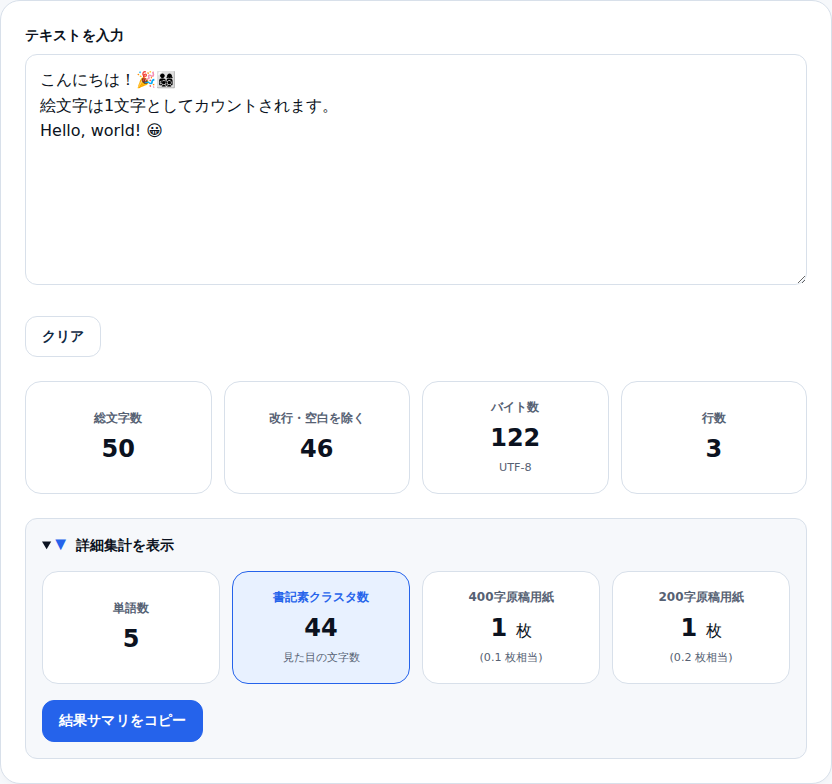
👨👩👧👦 を貼り付けると:
- 書記素クラスタ: 1(見た目通り)
- 総文字数(String.length): 11(内部コード単位)
- UTF-8バイト数: 25(実際のデータサイズ)
3つの指標を比べると、API のレート制限・DBのカラム長・SNS の文字数制限がどの指標に基づくかを把握できます。
まとめ
Intl.Segmenter は「人間が見て1文字」という直感的な単位でテキストを扱うための標準 API です。ポイントをまとめます。
- なぜ必要か:
String.lengthは絵文字・結合文字で人間の感覚と一致しない - 何ができるか: 書記素クラスタ単位のカウント・切り捨て・分割
- いつ使うか: 文字数制限 UI・テキスト切り捨て・SNS 投稿補助ツール
- 注意点:
granularity: 'word'は日本語ロケール指定が重要、大量テキストではuseDeferredValueと組み合わせる
フォームや入力系コンポーネントで文字数カウントを実装するときは、最初から Intl.Segmenter を選ぶことをお勧めします。
あわせて読みたい
同じテーマ・関連ツールの記事です。